Thanks to all DataLovers!
ON JUNE 27, 2019 – PAN PIPER, PARIS


The data centric conference in Paris
DataXDay is the data centric conference created for developers and enthusiasts.
Our vocation is to share ideas and visions around topics like data processing, streaming, data science, dataOps and security.
For the second edition of DataXDay, data experts will be giving you insights on the latests trends and sharing knowledge about data engineering and data science.
")
")
250 attendees


For developers and Tech Leads


One Day
DataXDay will cover the following topics

Applied Machine Learning Done Right
Data science goes beyond prototyping and experimentation. What are the recipes to create valuable and good quality data products? Come learn about how machine learning integrates business workflows and the ways AI and deep learning impact industry.


Reactive First
The trends in building applications are moving fast and they are coming with new ways to deal with data everyday. Things like stream processing, change data capture, microservices and serverless are changing the vision of what efficient data pipeline should look like.


Data Intimacy
Data has become essential for businesses, it is vital to secure it. Join us to explore the latest architecture standards, craftsmanship techniques and security patterns to ensure data privacy on the cloud or on premise infrastructures.

Program
8h30 - 9h
Welcoming & Breakfast
9h - 9h05
Opening


Caroline Goulard
CEO, Dataveyes
Conférence en français 🇨🇵


Michaël Figuière
Software Engineer, Facebook
Conference en anglais 🇬🇧


Xavier Leaute
Software Engineer, Confluent
Reactive First
Conférence en anglais 🇬🇧
Learn how we optimized one of the more complex Kafka Streams applications we run at Confluent today. In the process you will become familiar with how to analyze and profile applications using tools such async-profiler and Java Flight Recorder. In the context of stream processing, this means understanding runtime behavior both at the JVM level, as well as interaction with the native libraries we often heavily rely on. We will explain how to identify bottlenecks, not only in terms of cpu usage, but also understand where your code might be blocking unexpectedly. This talk will go deep down the rabbit hole, from the high-level application structure down to lower-level system calls and back out. Today you need to be able to analyze applications not only on bare-metal but also in a container-based world, so we will also talk about the intricacies of performing some of those operations in Docker-based deployment models.
Par Xavier Leaute - Software Engineer, Confluent
10h30 - 10h50
Deep learning en production vu par un Data Engineer


Romain Sagean
Développeur Data - Xebia
Applied Machine Learning Done Right
Conférence en français 🇨🇵
Vos collègues Data Scientists ont choisi un modèle de Deep Learning, charge à vous d’assurer son industrialisation.
Comment paralléliser vos prédictions ? Êtes-vous obligés de mettre du Python en production ? Comment réentrainer le modèle à l’échelle ? Comment suivre ses performances ?
Autant de défis que nous avons relevés et dont nous vous partageons les solutions.
Par Romain Sagean - Développeur Data - Xebia
10h50 - 11h15
Break


Kai Waehner
Technology Evangelist - Confluent
Applied Machine Learning Done Right
Conference en anglais 🇬🇧
This talk shows how to productionize Machine Learning models in mission-critical and scalable real time applications by leveraging Apache Kafka as streaming platform. The talk discusses the relation between Machine Learning frameworks such as TensorFlow, DeepLearning4J or H2O and the Apache Kafka ecosystem. A live demo shows how to build a mission-critical Machine Learning environment leveraging different Kafka components: Kafka messaging and Kafka Connect for data movement from and into different sources and sinks, Kafka Streams for model deployment and inference in real time, and KSQL for real time analytics of predictions, alerts and model accuracy.
Par Kai Waehner - Technology Evangelist - Confluent


Stéphane Maarek
CEO - DataCumulus
Reactive First
Conférence en anglais 🇬🇧
Apache Kafka has real-time capability and everyone knows that! The real challenge facing engineers comes from re-designing the existing data pipelines from batch to real-time. In this talk, we will do a case study on how to build an end-to-end real-time data pipeline by building four micro-services on top of Apache Kafka. It will give you insights into the Kafka Producer API, Avro and the Confluent Schema Registry, the Kafka Streams High-Level DSL, and Kafka Connect Sinks.
Par Stéphane Mareek - CEO - DataCumulus
12h55 - 14h
Lunch


Jonathan Winandy
Dirigeant fondateur - Univalence
Reactive First
Conférence en français 🇨🇵
Avez-vous déjà rencontré un bug vraiment prise de tête ? Avez-vous souhaité pouvoir juste faire un ctrl-Z ?
Bien que les micro-services soient plus complexes à exploiter que leurs homologues monolithiques, ils laissent place à des architectures qui nous permettent d'analyser et de corriger les erreurs du passé et nous évitent des surprises dans le futur.
Après un rappel rapide sur le tracing distribué, nous verrons comment avec un Kafka récent et Jaeger on peut construire un système complet avec:
- l'unification et la compression des données,
- l'analyse de la cause et de la source des bugs et des effets,
- le ``voyage dans le temps``.
Aucune connaissance préalable de ``Dapper`` et du fonctionnement des cabines téléphoniques sont requises ! 😉
Par Jonathan Winandy - Dirigeant fondateur - Univalence


Guillaume Michel
Machine Learning Engineer - Netatmo
Applied Machine Learning Done Right
Conférence en anglais 🇬🇧
Automated neural network architecture search (NAS) is a computation intensive task. Tools like Cloud AutoML have lower the technical barrier for adoption but they still lack the ability to optimize for multiple criteria at the same time. This talk presents the techniques we use at NETATMO to speed up Dvolver, our multi objective NAS engine and how we reduced 50 days of computations on a single GPU to a couple of days on multiple GPUs leveraging RabbitMQ, Docker and Kubernetes on Google Cloud Platform.
Par Guillaume Michel - Machine Learning Engineer - Netatmo


Olga Petrova
Machine Learning DevOps Engineer - Scaleway
Applied Machine Learning Done Right
Conférence en anglais 🇬🇧
Generative Adversarial Networks (GANs), praised as “the most interesting idea in the last ten years in Machine Learning” by Yann LeCun, the director of Facebook AI, are unsupervised machine learning algorithms that have been used to generate anything from human faces and hotel rooms to cats etc. Despite their unsupervised origin, GANs are now increasingly being used for supervised ML tasks, such as face frontalization and super resolution. In this talk, I will present an easy-to-grasp explanation for why a GAN architecture may be useful for achieving photo-realistic results, and discuss what types of supervised ML projects are most suitable for using GANs.
Par Olga Petrova - Machine Learning DevOps engineer - Scaleway
16h10 - 16h40
Break


Alban Perillat-Merceroz
Software Engineering Manager - Teads
Reactive First
Conférence en anglais 🇬🇧
This talk showcases how we built a platform that is capable of ingesting and transforming a stream of Billions of events a day using BigQuery, and how we use and abuse Redshift to deliver self-served, tailored views to many data visualisation clients and web apps.
Par Alban Perillat-Merceroz - Software Engineering Manager - Teads


Jacek Laskowski
Freelance IT Consultant
Reactive First
Conférence en anglais 🇬🇧
Let's talk about state management in Spark Structured Streaming. During this talk you will learn the streaming concepts that are particularly relevant for stateful stream processing in Structured Streaming, e.g. watermark and output modes, but also GroupState and GroupStateTimeout. We will be exploring simple stateful processing (with groupBy operator) and more advanced use cases with KeyValueGroupedDataset.mapGroupsWithState and the most advanced KeyValueGroupedDataset.flatMapGroupsWithState operator. In other words, you will learn how to use the stateful streaming API and understand the internals.
Par Jacek Laskowski - Freelance IT Consultant
18h20 - 20h
Meet and greet
Download the program (PDF)
8h30 - 9h
Welcoming & Breakfast
9h - 9h05
Opening (Room 1)
Caroline Goulard
CEO Dataveyes
Conférence en français 🇨🇵
Michaël Figuière
Software Engineer, Facebook
Conference en anglais 🇬🇧


Pauline Nicolas / Théo Bontempelli
Data Scientist / Data Engineer - Deezer
Data
Applied Machine Learning Done Right
Conférence en français 🇨🇵
Chez Deezer, le Machine Learning (apprentissage automatisé) est au cœur de nombreux aspects de l’application. Au sein de l’équipe analytics, nous travaillons sur différentes tâches telles que la prédiction et la prévision d’évènements, dans le but de fournir des retours utiles pour les équipes produit et business. Au cours des discussions avec ces équipes, nous avons réalisé que pour beaucoup de projets, l’accès en temps réel aux prédictions de nos modèles représentait un réel intérêt. Ce constat nous a donc amenés à exploiter l’ensemble des analyses réalisées dans nos notebooks afin de déployer nos algorithmes en production sous Spark.
Afin de réussir au mieux ces migrations, nous avons mis en œuvre un certain nombre de procédés, de la data architecture review à l’implémentation des modèles en Scala Spark. Pour illustrer cela, nous vous parlerons de notre retour d’expérience sur la prédiction du churn à Deezer et nous vous présenterons comment les data scientists et les data engineers ont travaillé ensemble à la réussite de ce projet.
Par Pauline Nicolas - Data Scientist - Deezer
et Théo Bontempelli - Data Engineer - Deezer


Thomas Franquelin
Staff Software Engineer - Contentsquare
Data Intimacy
Conference en anglais 🇬🇧
In the course of 3 years, ContentSquare changed its main data store twice! We first moved from Redshift to Elasticsearch, then to Clickhouse.
During this time, we had to deal with a vast increase in data volume, and support more and more features. How did we ensure that we didn’t break our application in the process?
We’ll talk about a simple way to achieve this by replaying production load to legacy and new systems at the same time, and studying statistical differences between the two in order to pinpoint regressions. We’ll see that this method also makes from a coarse-grained, but fairly realistic load testing.
Par Thomas Franquelin - Staff Software Engineer - Contentsquare
10h50 - 11h15
Break
11h15 - 12h00
Kubeflow : Tensorflow on Kubernetes


Laurent Grangeau / Sylvain Lequeux
Cloud Solution Architect - Sogeti / Consultant - Xebia
Applied Machine Learning Done Right
Conférence en français 🇨🇵
L’intelligence artificielle est en train de révolutionner tous les domaines : médecine, pharmacie, automobile, même l’informatique en lui-même. Mais la multitude d’outils mis à disposition des développeurs rend la portabilité et l’entrainement de modèle compliqué, non répétable et non scalable. Durant ce talk, nous verrons comment déployer Kubeflow, un projet tirant partie de la puissance de Kubernetes afin d’entrainer des modèles de Machine Learning basé sur Tensorflow. Nous verrons aussi comment grâce aux GPU et Kubernetes, nous pouvons accélérer la phase d’apprentissage de chaque modèle. Enfin, nous verrons comment entrainer un modèle de machine learning simplement grâce à JupyterHub.
Par Laurent Grangeau - Cloud Solution Architect - Sogeti
et Sylvain Lequeux - Consultant - Xebia


Tom Stringer / Antoine Isnardy
Junior Data Scientist / Data Scientist, NLP Lead - Quantmetry
Applied Machine Learning Done Right
Conférence en français 🇨🇵
Avec la multiplication des moyens numériques, une entreprise peut recevoir plusieurs milliers d'e-mails clients par jour. Un email est parfois transféré un grand nombre de fois avant que la bonne personne puisse le traiter, ralentissant ainsi le délais de réponse au client.
Le projet que nous présentons optimise le routage des emails en utilisant des algorithmes de traitement automatique du langage naturel. Il vise à pré-traiter les emails pour mieux les classer et les décrire par extraction de mots-clés. Le projet est actuellement en production à la MAIF, examinant 10 000 emails chaque jour. Il est maintenant disponible en open source sur http://github.com/MAIF/melusine.
Les différentes briques techniques reposent sur des méthodes statistiques complexes ainsi que sur des algorithmes d'apprentissage profond tels que les réseaux neuronaux à convolution.
Par Tom Stringer - Junior Data Scientist - Quantmetry
et Antoine Isnardy - Data Scientist, NLP Lead - Quantmetry


Nicolas Brigitte-Alphonsine
Co-fondeur et CEO, Nodata
Data Intimacy
Conférence en français 🇨🇵
Nous discuterons des clés pour un accès facilité à la donnée, qui s’appuie sur des modèles industrialisés, rapprochés aux référentiels et indicateurs existants. Nous aborderons également les contraintes de sécurité et de juridiction d’une telle architecture.
Par Nicolas Brigitte-Alphonsine, Co-fondeur et CEO - Nodata


David Leconte
Solutions Engineer - Datastax
Data Intimacy
Conférence en français 🇨🇵
Apache Cassandra™ est une base de données distribuée dessinée pour le cloud (résilience, scalabilité, réplication). Avec son architecture masterless et la communication peer-to-peer entre les noeuds, elle devient extrêmement pertinente pour les déploiements hybrides et/ou multi-cloud.
Dans cette session nous allons effectuer la démonstration d’une migration d’applications dans le cloud sans interruption de service. Nous aborderons les points techniques importants sous-jacents : réseau, architectures de déploiement, configurations, distribution de la donnée. Repartez avec les scripts pour reproduire la demo !
Par David Leconte, Solutions Engineer - Datastax


Alexis Dutot / Jade Copet
AI engineer / Head of AI, Linkfluence
Applied Machine Learning Done Right
Conférence en anglais 🇬🇧
At Linkfluence, we analyze millions of social media posts per day in more than 60 languages. This represents thousands of noisy user-generated documents per second passing through our internal enrichment pipeline. This volume combined with the real-time constraint prevents us from using cross lingual BERT-like models and in general makes it challenging to use computation-intensive deep learning models in production.
In this talk we will focus on multilingual sentiment analysis and emotion detection tasks based on social media data. Only a few annotated corpora tackle these tasks and the vast majority of them is dedicated to the English language. We will see how we fully exploit the potential of emojis as a universal expression of sentiment and emotion in order to build accurate sentiment analysis and emotion detection deep learning systems in several languages using solely English annotated corpora.
We will also discuss how we used Tensorflow optimizations and a novel deep learning architecture to make those systems efficient for our real-time conditions.
Par Alexis Dutot - AI engineer, Linkfluence
et Jade Copet - Head of AI, Linkfluence
14h55 - 15h15
Incremental Data Architecture


Walid Haouari
Data Engineer - Xebia
Data Intimacy
Conférence en français 🇨🇵
Le design d'architecture data n'a jamais été chose facile. On rencontre souvent des risques d'inadaptation au besoin, des faibles performances, des blocages paresseux voir un accomplissement partiel des objectifs de départ. Dans la plupart du temps, ces problématiques sont directement liées à un manque ou une mauvaise gestion des resources.
L'Incremental Software Architecture est une méthode de conception avancée qui va permettre d'outrepasser ces risques tout en garantissant des systèmes élastiques, efficaces et rentables.
Nous allons voir ensemble comment adopter cette approche favorisant la productivité, étape par étape, le tout dans un contexte Data.
Par Walid Haouari - Data Engineer - Xebia


Victor Landeau
Ingénieur Machine Learning - OUI.sncf
Applied Machine Learning Done Right
Conférence en français 🇨🇵
Chez Oui.sncf, cela fait maintenant plusieurs années que nous utilisons des algorithmes de Machine Learning dans certains de nos applicatifs en production. Mais cela n'est pas sans poser de problème, notamment du fait du caractère non-déterministe de ces approches.
En effet, comment peut-on développer sereinement des applicatifs dont les sorties attendues ne sont pas connues par avance ?
Pour répondre à cette problématique, nous avons développé notre propre stratégie de test, adaptée au monde incertain du Machine Learning. Cette approche se base sur trois grandes couches de tests que nous vous détaillerons dans ce Talk.
Par Victor Landeau - Ingénieur Machine Learning - OUI.sncf
16h10 - 16h40
Break
16h40 - 17h25
Les nouveautés Serverless de GCP


Guillaume Laforge
Developer Advocate - Google
Data Intimacy
Conférence en français 🇨🇵
Des millions de personnes échangent des selfies sur Snapchat ou jouent à Super Mario Run tous les jours. Savez-vous où ces applications tournent ? C'est le vénérable Google App Engine et l'infrastructure de Google Cloud qui permettent aux développeurs de se focaliser sur leur code et de laisser le soin de scaler l'application à Google.
Que vous déployiez des applications avec App Engine, ou des fonctions avec Cloud Functions, vous ne vous souciez plus de serveurs ou de clusters à provisionner et vous payez proportionnellement à l'utilisation, sans coûts fixes.
Dans cette session, découvrons ensemble ce qu'il y a sous le capot et surtout les nouveautés ``serverless`` de Google au delà d'App Engine et Cloud Functions.
Par Guillaume Laforge - Developer Advocate - Google
17h35 - 18h20
Tensorflow 1.x n'est plus, vive Tensorflow 2.0


Alexia Audevart
Data & Enthusiasm - Datactik
Applied Machine Learning Done Right
Conférence en français 🇨🇵
TensorFlow est l'un des frameworks majeurs pour faire du Deep Learning. Cependant, si vous avez construit des modèles en utilisant TensorFlow 1.x, il y a des chances que vous ayez trouvé la courbe d'apprentissage un peu raide et l'utilisation pas toujours intuitive, surtout si vous avez utilisé les APIs bas niveaux ! Google et la communauté de développement de TensorFlow ont pris en compte les différentes remarques et ont repensé le framework pour le rendre plus facilement utilisable ! C'est ce que je vous propose de parcourir ensemble en faisant le lien avec la version précédente. Info importante, TensorFlow v1.x ne sera plus maintenue dès que la release de tensorFlow v2.0 sera dans les bacs 😉
Par Alexia Audevart - Data & Enthusiasm - Datactik
18h20 - 20h
Meet and greet
Tickets
Super Early Bird
30€
Sold out
Early Bird
70€
Sold out
Regular
95€
Sold out
Speakers


Caroline Goulard
CEO, Dataveyes


Michaël Figuière
Software Engineer, Facebook


Guillaume Laforge
Developer Advocate, Google


Alban Perillat-Merceroz
Software Engineering Manager, Teads


GUILLAUME MICHEL
Machine Learning Engineer, Netatmo


JACEK LASKOWSKI
Freelance IT Consultant


ROMAIN SAGEAN
Développeur Data, Publicis Sapient Engineering


Sylvain Lequeux
Consultant BigData, Publicis Sapient Engineering


LAURENT GRANGEAU
Cloud Solution Architect, Sogeti


OLGA PETROVA
Machine Learning DevOps engineer, Scaleway


JONATHAN WINANDY
Dirigeant fondateur, Univalence


KAI WÄHNER
Technology Evangelist, Confluent


STÉPHANE MAAREK
CEO, DataCumulus


WALID HAOUARI
Data Engineer, Publicis Sapient Engineering


Théo Bontempelli
Data Engineer, Deezer


Antoine Isnardy
Data Scientist | NLP Lead, Quantmetry


ALEXIA AUDEVART
Data &Enthusiasm, Datactik


VICTOR LANDEAU
Ingénieur Machine Learning, OUI.sncf


TOM STRINGER
Junior Data Scientist, Quantmetry


PAULINE NICOLAS
Data Scientist, Deezer


Xavier Leaute
Software Engineer, Confluent


JADE COPET
Head of AI, Linkfluence


THOMAS FRANQUELIN
Staff Software Engineer, Contentsquare


DAVID LECONTE
Solutions Engineer, Datastax


NICOLAS BRIGITTE-ALPHONSINE
Co-fondeur et CEO, Nodata


ALEXIS DUTOT
AI Engineer, Linkfluence
Meet and Greet
The Meet & Greet evening is the perfect time to discover DataXday, meet our sponsors, discuss with international speakers and other Data Lovers, in a relaxed atmosphere.
The inscription is free, but places are limited.
Contact & access
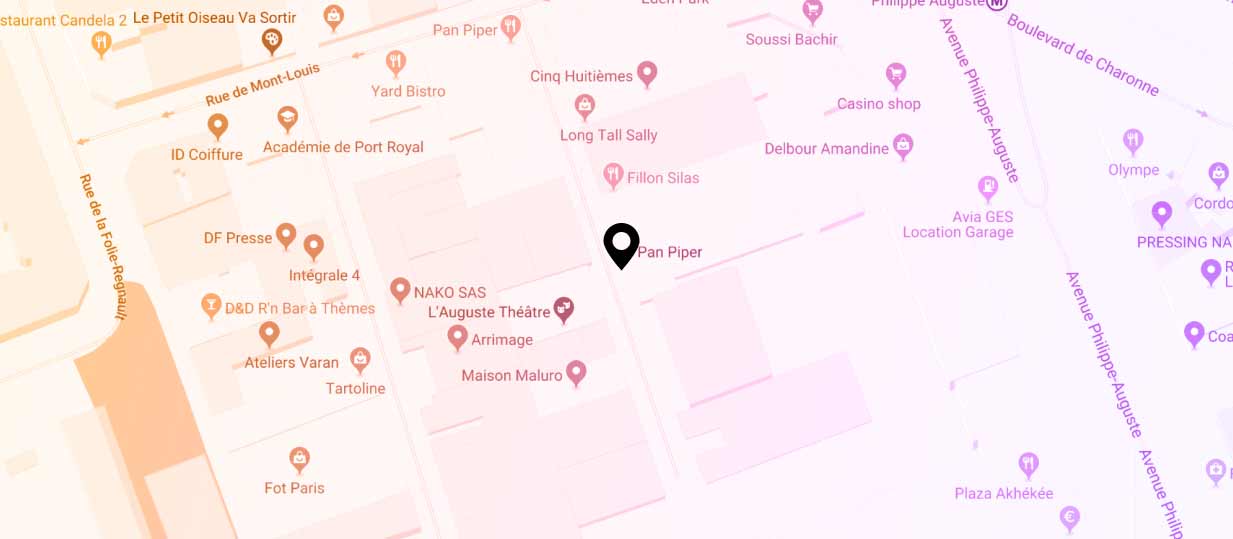
The venue is located in the 11th arrondissement of Paris, a few steps from Metro Station Philippe Auguste on Line 2 or a 5-minutes walk from Metro Station Charonne on Line 9.
COME TO THE CONFERENCE
PAN PIPER - 4 impasse Lamier, 75011 Paris

Sponsors
Sponsor Platinium
Sponsor Gold
With the support of








Brought to you by




Follow us on Twitter



















































